Not all documents read the same.
All four can become data with a codebook.
Text
Prose that's already text. Emails, articles, transcripts, clean PDFs.
Read the words.



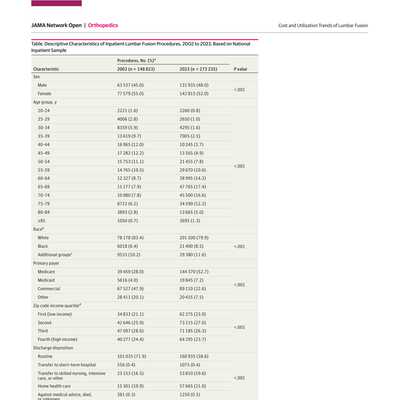
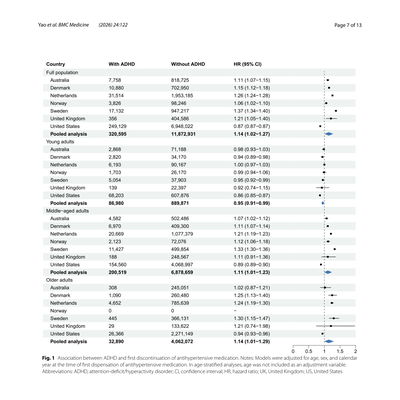
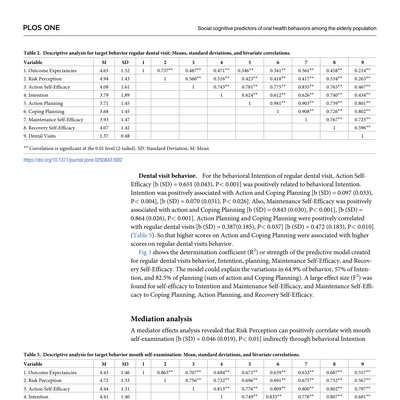
Scientific
Manuscripts, patents, reports. Figures, tables, equations — the evidence isn't only in the prose.
Read the text — and see the figures.
Visual
Forms, invoices, typed letters, well-scanned pages. The layout carries meaning.
Look before you read.
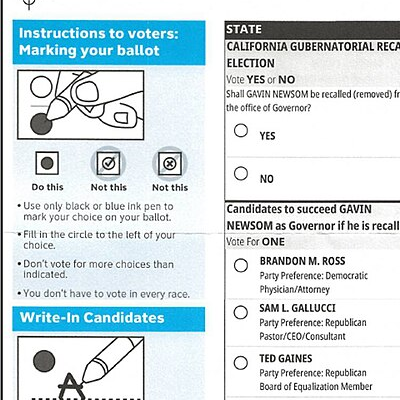


Squint
Ledgers, registries, field notes. The same structure on every page — clean or damaged.
Read each page the same way.


On Data Mint, we add more reader modes as we find document types that need them.
Four disciplines of reading. One extraction, on Data Mint.
No matter where you interface with AI: pick the reader that fits the document.
@karlrohe